
Day0 基础概念
C++工作原理:
预处理:
处理文件内的预处理语句,如#include、宏定义、条件编译(#if #endif)等。
把文本处理成实际的样子
主要任务:
- 宏替换:替换
#define定义的宏。 - 头文件展开:将
#include的头文件插入到代码中。 - 条件编译:根据
#ifdef等条件指令包含或忽略某些代码。 - 删除注释:移除所有
//和/* ... */的注释内容。
输出:
一个“无注释、无预处理指令”的纯C++代码文件,通常以 .i 或 .ii 为后缀。
编译
编译就是把处理后的代码文本,翻译成汇编的过程。
编译器会对源代码进行词法分析、语法分析、语义分析和中间代码生成(生成汇编)。
主要任务:
- **语法分析:**检查代码的语法是否正确
- **语义分析:**检查变量类型、函数调用等语义是否正确。
- **优化:**编译器对代码进行初步优化,移除无用代码、简单循环展开、常量折叠等
- **生成中间代码:**翻译特定架构的中间代码。
输出:
一个 .s 汇编文件,包含汇编指令。
汇编
汇编就是将汇编代码翻译成二进制机器码。
这一阶段由汇编器完成
主要任务:
- 将汇编代码翻译成,目标机器指令
- 生成目标文件,通常是二进制格式的
.o或.obj文件。
输出:
目标文件(.obj文件),包含机器码,但还不是一个可执行程序。
连接
链接阶段,将多个目标文件(.obj)及库文件合并,生成最终可执行文件(.exe)。
主要任务:
- **符号解析:**将函数或变量的声明和定义匹配(声明只是在编译期间保证通过语法检测,需要在连接阶段找到真正的函数定义)
- 库的连接:链接静态库(
.a/.lib)或 动态库(.so/.dll)。 - 地址分配:为每个符号分配内存地址。
- 合并代码段和数据段:将所有模块的代码和数据整合为一个整体。
输出:
一个最终的可执行文件,通常以 .exe 或无扩展名的形式存在。
完整的编译流程
- 预处理:将
file.cpp转换为file.i。 - 编译:将
file.i转换为file.s。 - 汇编:将
file.s转换为file.objj。 - 链接:将
file.obj转换为file.exe。
工具与阶段对应关系
| 阶段 | 输入文件 | 输出文件 | 工具 |
|---|---|---|---|
| 预处理 | .cpp 或 .cc |
.i |
预处理器 (g++ -E) |
| 编译 | .i |
.s |
编译器 (g++ -S) |
| 汇编 | .s |
.o |
汇编器 (g++ -c) |
| 链接 | .o |
可执行文件 | 链接器 (ld/g++) |
“->”和“.和“::”的区别
**-> **是指针指向其成员的 运算符
->前面放的是指针
指针->成员方法
1 | class Printable |
**:: **是域作用符
::前面放的是域性质的实体(类、命名空间等)
**::**是域作用符,是各种域性质的实体(比如类(不是对象)、名字空间等)调用其成员专用的。
(如果有个局部变量与全局变量同名(假设都是int a;),默认调用的 a 是局部变量,如果要访问全局变量a,就要这么写“::a”。使用域作用符来加以区别;前面没写具体的域名,就是指默认域)
例如调用类的静态函数or静态变量
类型::静态变量/静态函数
. 是成员作用符
. 是对象专用的,只有类实例化的对象才使用.
Day1 基本语法
注释
单行:
1 | // 注释内容 |
多行:
1 | /* |
和Python完全不一样啊属于是
Python
单行:
1 | # 注释内容 |
多行:
1 | """ |
其中C++还有个比较特别的东西
条件编译
1 |
|
当bool为真时,执行code,否则不执行。
可以在测试环境时让bool为真,在发布环境时让bool为假,从而实现不同环境下的代码执行。
输出输入
在C中,还是和Python用的差不多的,是用printf()
不过到了C++,有全新的东西:cout
cout作为C++的特色,在写C++语言时都偏向使用cout来输出文本到控制台。
使用cout而不使用printf的原因
- 类型安全
- 面向对象设计
- 易于扩展
类型安全
std::cout:通过 C++ 的 流插入操作符 (<<),可以避免手动指定数据类型。编译器会根据数据的类型自动选择正确的处理方式。
1 | int num = 42; |
这里 num 的类型自动匹配,不需要手动指定格式。
printf:需要手动指定格式(如 %d, %s 等),如果格式与变量类型不匹配,会导致未定义行为:
1 | int num = 42; |
面向对象设计
std::cout:是 C++ 标准库中的一个对象,体现了面向对象的设计原则,更加符合 C++ 的设计理念。
printf:是 C 的标准库函数,基于函数调用,缺少对象的灵活性。
易于扩展
使用 std::cout 可以通过重载 operator<< 为用户自定义类型实现输出:
这个后面学到类的时候再细看
<< endl的作用
- 换行符:会插入换行符 类似\n。
- 刷新缓冲区:会强制刷新输出缓冲区。确保之前的数据立即显示到终端或写入文件。普通的\n换行符并不一定会刷新缓冲区。
联合体
联合体是C++中一种数据结构,类似结构体struct
(在我看来 struct就是一个存放变量的类而已)
但是联合体有个很牛逼的特性:
- 就是联合体里面的成员,共享一块内存
除此之外,还有其他相关的特性:
-
它的所有成员相对于内存地址的偏移量都为0;即所有成员的内存地址都是从整个联合体的头部开始的。
-
联合体的内存空间,需要大到足够容纳”最宽“的成员;即联合体的内存占用大小取决于,占用内存最大的成员的内存大小。

Day2 递归、结构体、枚举、静态变量等
枚举
-
关键字 enum,代表声明的是一个枚举类型的数据结构
-
定义格式
1 | enum <类型名> {<枚举常量表>}; |
-
enum :表明后面的标识符是一个枚举类型的名字
-
枚举常量表:以标识符的形式表示的整型量
-
枚举常量、或者叫枚举成员,只能是整型常量。
成员为什么只能是整型常量?
- 历史原因: 枚举在 C 和 C++ 中的起源是替代
#define宏定义,提供一组有意义的整型常量,因此设计成整型。 - 性能和简洁性: 整型常量在底层实现中直接映射为数值,访问和比较高效。
- 用途特点: 枚举通常用来表示状态或选项,整型数值便于操作和存储。
其实就是宏的一种,作用也是和宏一样:定义一组有意义的整型常量。
在用的时候,需要定义一个枚举类型的变量,才能开始使用
-
使用格式:
1
枚举类型名称 枚举变量名称 = 枚举常量
要注意:
- 枚举常量的标识符不能相同,否则会造成命名冲突。(可以理解为不能有两个名字相同的宏定义就行)
静态变量
- 关键字 static,声明一个变量为静态变量
- static是一种 类型限定符
- 用于定义静态变量,表示该变量的作用域仅限于当前文件或当前函数内,不会被其他文件或函数访问。
随机数
Day3
指针
定义:指针是一个整数,一种存储内存地址的数字
指针只是指向内存中的一个位置,是一个整数 变量
基础用法:
1 | int main() |
指针:只是一个保存内存地址的整数
1 | ** 双指针,指向指针的指针(一个内存地址变量的内存地址,因为指针也是一个变量,也需要一个内存地址来存放) |
引用
引用是指针的语法糖,让指针更容易阅读、理解
一种引用现有变量的方法
必须引用已有的变量
例:
1 | int& a = b; // 初始化一个整形对象的引用 a,引用b |
引用能做的,指针都可以完成,引用只是指针的语法糖。
1 | void Incremenet(int* num)//传递指针,通过逆引用修改指针指向的对象的值 |
类和结构体的区别
类:
1 | class Player |
类中,参数的访问性默认是private的,只允许类内部访问。
而struct,默认是public的
技术上来讲,就只有参数的默认访问性不一样
结构体存在的意义是,为了向C向下兼容,因为C中并没有class,但是有struct
选择用那种,基本上是看编码习惯
例如struct,通常是定义一堆变量的集合,没有行为
class 则是定义 变量和行为的集合体,更
Day4
静态 static
有两种含义
类or结构体 外部使用static
代表这个 变量 或者 方法 只在当前翻译单元内部链接(在声明的文件内有效)
在链接阶段,不会在当前翻译单元外连接定义和声明
使用说明
1 | static int s_Variable = 5; |
如果在别的文件,想要使用这个静态变量,则需要通过extend
1 | extern int s_Variable; |
类or结构体 内部使用static
静态 变量会在所有类实例中共用内存
静态方法可以被调用,不需要通过类实例,而在静态方法内部
静态变量or方法的调用,通过::调用
1 | struct Entity |
且静态函数,不能使用非静态变量,因为静态函数不能引用到类的实例。
甚至可以看作是一个写在类外部的函数,只是因为分类or职能相同,所以放在了类里
意味着该变量实际上将与类的所有 实例 共享内存
局部静态Local Static
局部静态变量,允许我们声明一个变量,该变量的
生命周期:等于整个程序的生命周期
作用域:被限制在定义它的作用域内。
例如如果是在一个函数内定义,则只有这个函数能直接访问到这个局部静态变量,但是这个变量在离开作用域后不会被销毁,而是继续存活着
下次再调用这个函数,不会重新创建这个变量,而是返回已有的
最经典的用法就是单例模式
1 | class Singleton |
通过Get获取的实例,都是同一个,可以通过Get来获取类的单例。
这里返回需要返回对象的引用,如果没有&符号,会返回这个对象的复制对象,就不是单例了。同理static Singleton instance的作用就是在第一次调用的时候实例化Singleton类,并且之后的调用中直接返回这个实例,不会再创建。
枚举
枚举:是整数,将一组数值集合作为类型,而不是仅仅用整型作为类型
一堆同类的数值,为了方便阅读代码,把一些有意义的整数枚举出来。
例子:
1 | class Log |
构造函数
可以理解为Python中的 __init__,负责对象的初始化
在类实例化对象时会自动调用。
而C++中的构造函数,是命名和类一样的函数。
例子
1 | class Entity |
而我们可以通过把构造函数私有化,不允许外部调用构造函数,来实现单例模式
1 | class Log |
析构函数
假如手动在 堆分配了内存,需要手动在对象销毁的时候手动释放内存,否则会造成内存泄漏。
通常不会手动调用。析构函数就是构造函数前面多加个~
例子:
1 |
|
Day5
继承
继承没什么好说的,面向对象的基础
不过c++里面,继承还有访问修饰符,public、private这些
语法:
class 类名 : 修饰符 父类名
例如
1 | class Entity // 实体类 |
虚函数
定义
虚函数是为了允许在子类中,重写父类的方法。(函数名相同,参数也相同)
相关知识点:
虚函数表(Virtual Table)简称vtbl
通过关键字 virtual 声明函数为虚函数,只有声明了虚函数的函数才能被子类重写,否则调用类的方法会调用到父类的方法。
例子:
1 | class Entity //父类 |
大概说明一下虚函数的实现原理:这里应该也是面试会问到的问题,就按照面试的答案来吧。
实现原理:
虚函数表(vtable)
- 当类拥有>=一个虚函数时,就会拥有一个自己的虚函数表。它是一个指针数组,每个元素都是函数指针。
- 如果派生类覆盖了基类的虚函数,虚函数表中的指针,就会被替换成派生类实现的函数的函数指针。
虚指针(vptr)
- 每个拥有虚函数的类,都会隐式地包含一个虚指针(vptr,在编译期间,编译器机制会自动补充虚指针的初始化),这个虚指针指向当前对象所属的虚函数表。
- 当通过对象调用虚函数时,编译器通过虚指针找到虚函数表,再通过函数的偏移量找到对应的函数指针,再找到对应的函数。
调用流程
- 通过基类指针或引用调用虚函数时:
- 通过对象的虚指针找到虚表。
- 从虚表中查找对应的函数指针。
- 调用函数指针指向的函数。
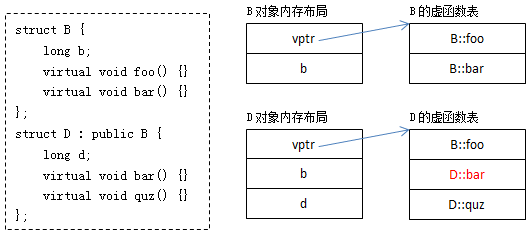
子类如何替换虚函数
子类继承父类时,虚表的构造方式如下:
- 继承虚表
- 子类的虚表开始时会拷贝父类的虚表。
- 覆盖虚函数
- 如果子类重写了某个虚函数,虚表中对应的位置会被替换为子类实现的函数指针。
- 新增虚函数
- 如果子类新增了虚函数,虚表中会扩展新的条目。
动态绑定与静态绑定
-
静态绑定
(非虚函数):
- 函数调用在编译时解析,直接生成具体的函数地址。
- 比虚函数调用效率更高。
-
动态绑定
(虚函数):
- 函数调用在运行时解析,通过虚表实现。
- 需要额外的指针查找和表查询,因此略有性能开销。
常见问题:
(1) 为什么构造函数中不能调用虚函数?
- 在构造函数执行期间,虚指针可能尚未初始化或仍指向基类的虚表。
- 因此,调用虚函数时不会有动态绑定,而是直接调用基类版本。
- 虚函数表的创建需要用到类对象,但是在调用构造函数前,类对象还没被生成,所以构造函数无法是虚函数
(2) 为什么析构函数应该是虚函数?
- 如果基类指针指向派生类对象,而基类析构函数非虚,则只调用基类的析构函数,导致派生类的资源未释放。
- 使用虚析构函数确保派生类的析构函数被正确调用。
总结
- 如果基类希望函数可以、应该被子类重写,那这个基类的函数就应该声明为虚函数
- 虚函数通过虚指针和虚表实现
- 虚指针编译期间自动生成
- 虚表是一个函数指针数组,每个类有自己的虚表
- 拥有虚函数的类,对象的内存布局中,通常第一条是vptr指针
纯虚函数(接口)
虚函数其实就是接口,在接口类写的纯虚函数,没有函数体,子类必须要实现纯虚函数的实现。
纯虚函数允许我们在基类中定义一个没有实现的函数,然后强制子类去实现该函数。
例子
1 | class Printable |
就是接口
可见性
可见性修饰符
- private
- 完全隐藏:仅当前类可见,甚至子类都不能访问
- 使用场景:
- 用于封装类的内部实现细节,不希望外界或子类直接操作这些成员。
- protected
- 对外不可见、继承时可访问:仅当前类以及子类可见
- 使用场景:
- 保护类的内部状态,使得只有子类能够操作或访问这些数据。
- public
- 完全公开:类的成员在类外部可以直接访问。
- 使用场景:
- 对外提供接口(如 getter/setter 函数、构造函数等)。
- 让外部直接访问不需要隐藏的信息(变量、函数等)。
Day6
数组
定义:
在一个变量中有多个变量,这个变量称作数组。
它可以存储一个固定大小的相同类型元素的顺序集合。数组是用来存储一系列数据,但它往往被认为是一系列相同类型的变量。
内存布局
数组在内存中以连续的形式存储
1 | int main() |
内存视图

由于是int型数组,int型占4个字节,这里5个元素,所以在内存上是20个连着的字节
声明数组
1 | type arrayName [ arraySize ]; |
-
type 可以是任意有效的 C++ 数据类型
-
arrayName是数组名
-
arraySize 必须是一个大于零的 整数常量
例:
1 | double balance[10]; |
现在 balance 是一个可用的数组,可以容纳 10 个类型为 double 的数字。
初始化数组
在 C++ 中,您可以逐个初始化数组,也可以使用一个初始化语句,如下所示:
1 | double balance[5] = {1000.0, 2.0, 3.4, 7.0, 50.0}; |
数组内所有元素都赋值为50.0
1 | balance[4] = 50.0; |
访问数组元素
这个也是依赖下标
1 | double salary = balance[9]; |
注意下标不要超出边界,在原始数组内,并不会做边界检测,假如操作了数组以外的内存,有可能会改变现有变量的值,导致依赖之外的异常。
静态数组
-
静态是在栈里创建的,在离开当前作用域后
{} 花括号后就会销毁 -
定义时就已经在 栈 上分配了空间大小,在运行时这个大小不能改变
1 | int example[5]; |
动态数组
- 运行时在 堆 上分配一定的存储空间,另外在运行时还可以改变其大小。
- 虽然在栈上分配空间效率较高,但是栈空间有限,对于大型数据应使用new和delete在堆区分配空间
1 | int* another = new int[5]; |
由于动态数组的生命周期是直到程序结束,所以需要手动调用释放数组占用的内存,否则会造成内存溢出
1 | delete[] another; // 释放动态分配的内存 |
字符串
定义
字符串, 实际上是是 字符 数组 ,是一堆字符的集合。在c++标准库中,一个char占用一个字节(因为主要是英文,一个16进制的字节足够用了)

主要是学习一下字符串的一个工作原理、
本质上是char字符的数组,就像上面编辑器显示的,双引号 “” 会隐式地转换成字符数组
内存布局
由于字符串本质上是数组,所以也是在内存中以连续的形式存储

由于char占用1个字节,所以 “John” 由4个字节组成,注意末尾由00作为字符串结束符,
1 | const char* name = "John"; // 会自动添加'\0' |
由于本质上是数组实现的,所以也可以这样输出字符串
1 | char name2[7] = {'M', 'u', 'k', 'P', 'u', 'n', '\0'}; // 必须手动添加 字符串结束符,否则会输出后面的乱码 |

这种直接操作 char[] or char* 是C语言的风格
c++中是建议使用 std::string
通过指针、字符串数组等形式定义字符串,是C语言的风格,C++为了向下兼容,所以前期也沿用的这种风格
1 | const char* str = "Hello, world!"; |
但是C++11之后,退出了 std::string
初始化字符串变量
1 |
|
std::string 常见操作
| 操作 | 示例代码 | 说明 |
|---|---|---|
| 获取长度 | str.size() 或 str.length() |
获取字符串长度 |
| 拼接字符串 | str1 + str2 或 str1.append(str2) |
拼接两个字符串 |
| 访问字符 | str[0] 或 str.at(0) |
访问字符串中某个字符 |
| 子串 | str.substr(pos, len) |
从 pos 开始,长度为 len 的子串 |
| 查找子串 | str.find("sub") |
返回子串首次出现的位置(找不到返回 npos) |
| 替换子串 | str.replace(pos, len, "new") |
替换从 pos 开始,长度为 len 的部分 |
| 插入字符串 | str.insert(pos, "inserted") |
在 pos 位置插入字符串 |
| 删除字符或子串 | str.erase(pos, len) 或 str.pop_back() |
删除从 pos 开始,长度为 len 的部分 |
| 比较字符串 | str1.compare(str2) |
返回 0(相等),正值(大于),负值(小于) |
| 转为 C 风格字符串 | str.c_str() |
返回指向内部 C 风格字符串的指针 |
Day7
常量 Const
定义:用于表示固定不变的数据或限制修改权限
1. 表示不可修改的数据(定义常量)
这是常量的最基本用途,即用于声明固定值,确保程序运行中这些值不会被意外修改。
使用场景
- 表示程序中的固定值,比如物理常量、配置参数、默认值等。
- 替代宏定义(
#define),具有类型检查能力,增强安全性。
例子:
1 | void Const() |
- 优点:编译器会强制保证
MAX_SIZE的值不可修改。 - 好处:相比宏,
const常量有明确的类型,可以被调试器识别。
这里要明确的说明一下常量指针和指针常量的定义和区别
常量指针
- 指向常量的指针
int const* a = new int;,const在*前面,叫做常量指针- 指针指向的内容不可改
例子
1 | // 指向常量的指针 这个常量不可改变 |
指针常量
- 指针本身是常量
int* const b = new int;,*在const前面。叫做指针常量- 指针本身内容不可修改
例子:
1 | // 指针本身是常量, 指针本身不可修改 |
指向常量的指针常量:
1 | const int* const a = new int; // 这个指针指向的内容,以及这个指针本身不可改 |
2. 修饰函数参数(只读参数)
当函数的参数加上 const 修饰后,表示在函数内部不能修改该参数的值。这种设计增强了代码的安全性和可读性,尤其是在以下两种场景中:
1 | void printValue(const int value) { |
2.2 修饰指针或引用参数
当函数通过指针或引用传递参数时,const 可以防止函数修改传递的对象。
- 指针示例:
1 | void display(const char* str) { |
- 引用示例:
1 | void printVector(const std::vector<int>& vec) { |
优点
- 明确参数只读属性,避免误修改。
- 提高函数的通用性,尤其在处理大对象时。
3. 修饰成员函数(保证对象状态不变)
在类中,const 可修饰成员函数,表示该函数不会修改对象的状态。这种设计可以提升代码的健壮性和安全性。
使用场景
- 设计访问器(getter)或只读方法。
- 确保特定操作不改变对象的成员变量。
例子:
1 | class Entity |
底层机制
在 const 成员函数内部,this 指针类型为 const ClassName*,因此不能通过 this 修改成员变量。
mutable
如果某些成员变量需要被修改,可使用 mutable 关键字:
1 | class MyClass { |
总结:
| 用途 | 作用 | 示例 |
|---|---|---|
| 定义常量 | 表示不可修改的固定值 | const double PI = 3.14; |
| 修饰函数参数 | 防止参数在函数内部被修改,增强安全性 | void display(const std::string& str); |
| 修饰成员函数 | 保证成员函数不会修改对象状态,支持常量对象调用 | int getValue() const; |